2023: Year of social media coding
I had different plans for this year… then, Elon Musk happened.
Elon took over Twitter in October last year, which set many different processes in motion. A lot of people I liked and followed started leaving the platform. Mastodon and the broader Fediverse, which has been slowly growing for many years but never got anything close to being mainstream, suddenly blew up with activity. A lot of those people I was following ended up there.
Then, Twitter started getting progressively worse under the new management. Elon’s antics, the whole blue checks / verification clusterfuck, killing off third party apps and effectively shutting down the API, locking the site behind a login wall, finally renaming the app and changing the logo – each step made some of the users lose interest in the platform, making it gradually less interesting and harder to use.
Changes, so many changes… and things changing meant that I had to change my workflows, change some plans, build a whole bunch of new tools, change plans a few times again, and so on. My GitHub looks like this right now, which is way above the average of previous years:
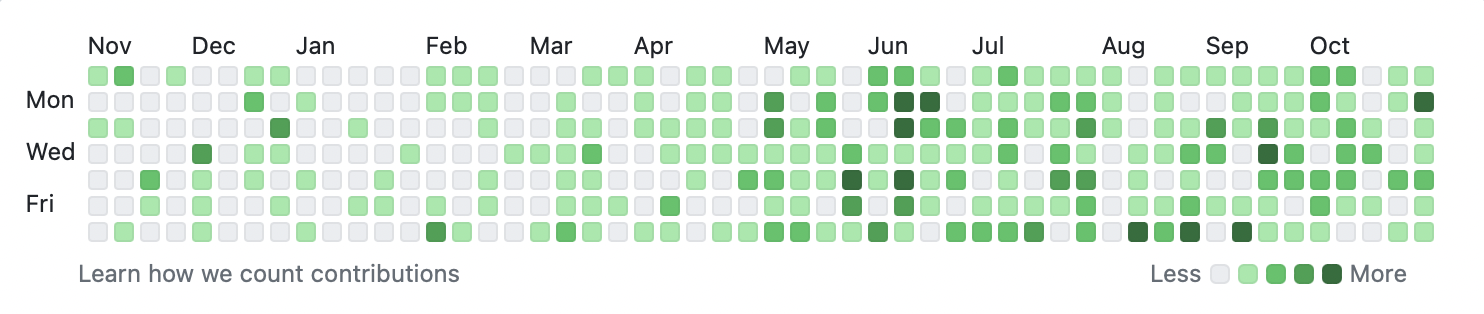
As usual, I ended up writing way more Ruby and JavaScript than Swift, which goes a bit against my general career plans – but I’ve built so much stuff this year and I had a ton of fun doing it. So in this blog post, I wanted to share some of the things I’ve been working on lately.
The Dead Bird Site 🦤
I had a bunch of private tools written for the Twitter API. For example, I had a script that downloaded all tweets from my timeline and some lists to a local database. I was also running various statistics on tweets, e.g. which people contribute how much to the timeline and list feeds, and automatically extracted links from tweets from some selected lists.
And then Elon shut off access to the API (unless you can afford $100 per month for a “hobbyist” plan), which meant I had to try to find other ways to get that data.
I quickly got the idea that I could somehow intercept the JSON responses that the Twitter webapp (I refuse to call it the new name, sue me) is loading from the JavaScript code. The JSON responses are very complicated with a lot of extra content, but they do contain everything I need. The problem is how to get them; I wanted to get data from my personal timelines, so I couldn’t do anonymous requests, and I didn’t want to make authenticated requests for my account from some hacked-together scripts, for fear of triggering some bot detection tripwire that would lock my account.
So the approach I settled on was to passively collect the requests in the browser, using Safari’s Web Inspector, and export them to a HAR file that can be parsed and processed like the data from the public API. (It would be even better to have a browser extension that intercepts XHR calls on twitter.com automatically, but as far I can tell, there is no way for request monitoring extensions to look at the content of responses, unless you inject scripts to the site.)

I initially tried to implement it as a Mac app, which gave me a chance to start experimenting with Core Data a bit. But in the end, I rewrote it in Ruby and released it as gem I called “BadPigeon” – named after the friends who visit my balcony every day 🐦
The gem is designed to output extracted data in the same form as the Twitter API, in a way that can be plugged into the popular twitter gem, so I could use all existing tools I had written with very little changes. The obvious downside is that it needs some manual help with the recording first, but I can live with that. I’ve been using this setup since June and it works pretty well for me so far.
I had one more Twitter-related project that I sadly had to shut down though – the Rails Bot which has been running non-stop since 2013, mostly unattended, picking and retweeting tweets from some developers in the Ruby community. It requires access to the API to fetch its home timeline periodically from crontab, so I couldn’t make it work this way.
∕ bad_pigeon
A tool for extracting tweet data from GraphQL requests made by the Twitter website 🐦

Mastodon’t 🦣
As the migration of developer communities out of Twitter started, I was initially skeptical; looking back, I guess I just had to go through the “five stages of grief” at my own pace… I also didn’t initially see the change as that bad as some others did, and to be honest I still don’t – to me, Twitter still isn’t literal hell on Earth, it’s just that month after month, it got progressively less useful, less interesting and more annoying.
So I finally started looking at Mastodon with interest. The idea of the “Fediverse”, a distributed system of many independent servers with a completely open API, where I don’t need to pay absurd prices for an access key, don’t have monthly download limits and which can’t be taken over and locked down, was appealing to me.
You see, I’m a bit crazy about data hoarding and processing information – for many years I’ve been having various ideas about tools I could write to somehow automate finding more relevant content in the noise of social media, to let me waste less time on it while still finding what’s important (the Rails Bot was a very early example of that). So I thought that maybe in this new open world, where the only limit is my imagination, I could build any tools I ever wanted and share them with others.
Well, turns out it’s not that simple…
It’s true that the Mastodon APIs are completely open and generally permissionless; for example, you can easily download any account’s complete history of “toots”, going as far as a few years back, anonymously. The problem is that there is a certain culture of the existing community of the Fediverse that was there way before the great migration, which is extremely against any kind of data collection, archiving and indexing. Making information searchable – information which is broadcasted in the open to the world – is seen as a threat to safety, and anyone who attempts that is labelled a “tech bro”, derided and attacked.
Sometime in winter I went down the rabbit hole of many, many threads discussing several of such tools, with the authors being attacked and told that they shouldn’t have built them. Just by mentioning in one of the threads that I’m thinking about building a Mac app that allows you to search the history of your home timeline, I got called out on “#fediblock” (Fediverse’s popular channel for warning about bad actors) as someone worthy of blocking.
All of this has very quickly cured me of any ideas to build pretty much any public tool for the Mastodon API. I just don’t have the energy and mental strength to deal with people attacking me this way for simply building tools on an open API that they don’t like.
What I ended up doing though was setting up my own personal Mastodon instance, martianbase.net. I joked that I’m probably the only person who hates Mastodon and also has their own Mastodon instance… But the first instance I signed up on last year was shut down unexpectedly, giving me no chance to migrate the account. That’s another thing I dislike about the ActivityPub system – your account identity and data is bound to the domain of your instance, and there is no easy way out if your admin misbehaves or disappears, or just has a different view on which other servers you should be able to talk to. So at that point I decided not to trust another instance admin, but to set up my own place, so that I can have full control over it.
Blue skies ahead 🌤
And then, just as Twitter was slowly going down and Mastodon has disappointed me – I started hearing about Bluesky.
Started as an idea of Jack Dorsey from Twitter back in 2019, with a goal of building a “decentralized Twitter” that Twitter itself could possibly one day be a part of, the project has been going on for a few years, and just as the whole Twitter chaos started, Bluesky got to the point where it could be presented to the world.
(Important note here, since media has widely promoted Bluesky as “Jack’s social network” and his name puts a lot of people off: it’s not in fact Jack’s social network. He’s not the CEO (a woman named Jay Graber is), he does not manage or control the company, and AFAIK he’s actually been very little involved in it recently, having mostly switched his interest to Nostr – to the point that he has even deleted his Bluesky profile.)
The attention and interest that Bluesky has received after lauching an invite-only beta has widely exceeded the team’s expectations, but this was both a blessing and a curse. They weren’t really prepared to run a real Twitter competitor that could accept the “refugees” escaping Elon’s playground. The thing is, they were mostly focused on the underlying protocol before, and the site itself has been launched as a bit of a demo. A lot of things that people consider pretty essential in a social networking site weren’t ready. But the team – which at that point was less than 10 developers in total, AFAIK – started adapting to the new reality, working as hard as they could to make the site usable for much larger crowds that they had been planning to.
I got access to Bluesky in late April. I don’t want to get into too much detail here about what it’s like, how it’s evolved since then and so on – I’m going to write a few more blog posts about Bluesky specifically. But long story short, I was completely hooked from day one.
Yes, it’s invite-only, has a much smaller userbase than the Fediverse, it’s an early beta, it doesn’t have videos, gifs or even hashtags. The iOS/Swift developers there are as rare as a unicorn. But it has a really nice community of users, third party developers who hack on various tools and help each other, and team members who interact with us on the site all the time. It looks and feels more like Twitter than Mastodon does, and it somehow just feels more fun to be on.
But the thing that excites me the most is the AT Protocol it’s built on and its potential. It’s a completely open federated protocol, just like ActivityPub that Mastodon uses, and it’s intended to eventually create another “fediverse” of distributed social apps (though the federation part is not live yet, but coming soon). It’s designed to take some lessons from what doesn’t work well in ActivityPub (and would be hard to change) and design the architecture better. For example, it uses “Decentralized IDs” (DID) independent of the hosting server to identify accounts, which makes it easy to migrate accounts between servers (and your handle can be any domain name you own, like @mackuba.eu).
The code it’s running on is open source, the APIs are completely open, and it all just invites you to write some tools and libraries for it – to be the first person to write a Ruby library, a Swift SDK, a command line client, a website with statistics. To be the first to plant a flag where others will come later.
I’ve been spending most of the time since April working on one Bluesky-related project after another, sometimes switching between a few in parallel. In the rest of this blog post, I wanted to show you some of the things I’ve been busy building:
Minisky
On the first day after I got in, I already started digging in the API and I wrote a small Ruby script for archiving my timeline and likes (of course I did…). This eventually evolved into a Ruby gem I called Minisky, which provides a minimalistic API client that handles logging in, refreshing access tokens, making GET and POST requests to the API and returning parsed JSON responses.
It doesn’t include any higher-level features like “get posts”, you have to know the name of the endpoint, what params to pass and what fields it returns, but it handles all the basic boilerplate for you. I use it as a base for some internal scripts, and for manually getting or sending some data to the API in the Ruby console. If you want to start playing with the Bluesky API or build some more specific tool that uses it, you can give this library a try (see the example folder for some ideas). It has no dependencies apart from Ruby stdlib.
∕ minisky
A minimal client of Bluesky/AtProto API
Custom feeds on Bluesky
Bluesky has a really cool feature that I think is pretty unique among all the social networks. On social sites, you normally have either a reverse-chronological timeline of posts from the people you follow, or some kind of algorithmic “home” feed that mixes them up with other suggested posts, in a way that you usually don’t fully understand and may not like (or both of these feeds).
Bluesky has both of these, but it also lets anyone build a custom feed that selects and orders posts however you like, and most importantly, lets you make this feed available to everyone else. Custom feeds are a core feature of the app; it lets you browse popular feeds from other people, feeds are listed in a separate tab on the feed author’s profile, and you can “pin” the feeds you use often, which puts them in the top bar in the mobile app, as if it was another built-in timeline. People build all kinds of feeds – thematic feeds like various scientific or art or NSFW feeds, feeds for specific communities like “Blacksky”, general “top posts this week” feeds, or different variations of an algorithmic “home feed” using various approaches.
The way the feeds work is that you need to provide an HTTP service on your server which implements a couple of endpoints. The Bluesky server then makes a request to your service on user’s behalf when they want to view the feed, and your service should respond with a JSON that includes a list of post URIs. Bluesky then takes these URIs and turns them into full post JSONs that it returns to the client.
When the team launched this feature back in May, they included a sample feed service project implemented in TypeScript. But I’m not a big fan of JS/TS and Node, so of course I had to reimplement it all in Ruby :]
I’ve spent quite a lot of time working on the feeds and related code this summer, and the result of this is three separate Ruby projects that I’ve open sourced on GitHub (in addition to my main project which is private).
BlueFactory
The first part is an implementation of the feed service itself. I based it on Sinatra, and it implements the three API endpoints required from a feed service. You need to provide some configuration (hostname, DID of the owner etc.) and your custom class to call back to in order to get the list of post URIs and the feed metadata. If you want, you can further customize the server using the Sinatra API, e.g. adding some custom routes with HTML content.
Feeds can generally be divided into two categories: general and thematic feeds that return the same content for everyone, and personalized feeds that show the feed from a specific user’s perspective. The latter are usually much more complicated to build, since you will often need much more data of different kinds to generate the response, depending on your algorithm. If you want to build a personalized feed, the request includes a JWT token that you can use to get the requesting user’s DID, and the gem can pass that as a param to your class (although note that at the moment it does not verify the token, so it can be easily faked).
∕ blue_factory
A simple Ruby server using Sinatra that serves Bluesky custom feeds
Skyfall
To return the post URIs from the feed service, first you need to get the posts from somewhere. You could possibly get them from the API, but realistically, a much better option is to connect to a so-called “firehose” web service and stream and save them as they are created, keeping a copy in a local database.
The firehose streams every single thing happening on the network, live – every new and deleted post, follow, like, block, and so on. Depending on your specific feed idea, you will usually only need to keep a small fraction of this data, e.g. only posts and only those that match some regexps – but you need to parse it all first to know what to keep. What further complicates things is that the firehose data does not come in a JSON form, but instead uses a bunch of binary protocols originated from IPLD/IPFS.
The second Ruby gem is meant to simplify this for you. It uses an existing CBOR library to do some of the binary protocol parsing and faye-websocket for the websocket connection. It connects to the firehose websocket on a given hostname and returns parsed message objects with the info about specific add/remove operations and relevant JSON records.
The firehose (and the Skyfall gem) isn’t only useful for creating feed services – you could possibly use it for any other project that needs to track some kind of records from the network in real time, whether it’s follows (to create a connection graph of the whole network, or to track when a follower unfollows you), or blocks (to find out who is blocking you), or to monitor when you or your company or project are mentioned by anyone anywhere. I’ve also included an examples folder with some sample scripts in the repo.
∕ skyfall
A Ruby gem for streaming data from the Bluesky/AtProto firehose
Bluesky feeds template
This project puts the previous two together and combines them into an example of a complete Bluesky feed service, which reads posts from the firehose, saves them to an SQLite database and serves them on a required endpoint – basically a reimplementation of the official TypeScript example in Ruby.
This is a “template” repo, which means it’s not meant to be used as-is, but instead forked and modified in your own copy. The reason is there are simply too many things that you may want to do differently – deployment method, chosen database, specific data to keep etc., and making this all configurable would be an impossible task. Instead, I’ve extracted the “input” and “output” parts as separate gems that can be used directly, and you build the parts in the middle – but you can use this template project as a good starting point.
My own feed service project is a private repo, but I’m keeping it in a similar structure to this template and I’m manually backporting some fixes and new features from time to time.
∕ bluesky-feeds-rb
Template of a custom feed generator service for the Bluesky network in Ruby
My feeds
And now we get to the part that all of this was for – building my own custom feeds.
I mentioned earlier that I often think about and experiment with various ways to find most relevant content to me on social media. So when I heard about the custom feeds feature, I immediately had an idea to build a feed for Mac/iOS developers that filters only posts on this topic, using a long list of keywords and regexps (I’ve actually reused a lot of work I’ve done a while ago for an unfinished thing I played with on Twitter).
It took me a couple of months to build all the pieces of the “feed generator”, but I’ve launched the Apple Dev feed in July. It isn’t very busy so far, to put it mildly, because there still aren’t that many iOS devs on Bluesky 😅 But as of today, it has 35 likes – only 50 likes less than the other Swift feed :]
Apart from the iOS dev feed, I’ve also made a more general macOS users feed and a couple of other feeds that were mostly a proof of concept / playground while building the service, but a lot of people seem to find them useful anyway, so I’ve left them running:
Skythread
The last one of my Bluesky-related projects, also with a “sky” in the name (most of the third party projects so far have either the word “blue” or “sky” as part of the name 😄). And this one is written in JavaScript for a change.
If you use Twitter and/or Mastodon a lot, you probably have the experience of reading some complicated thread and getting lost, not knowing who replies to whom or if you haven’t missed a whole part of the discussion. These two display branching out threads a bit differently – Twitter hides some of the branches, while Mastodon shows all direct and indirect replies in one flat list. In both cases, it’s not a perfect solution for reading some heated “hellthreads” that branch out endlessly. For me, a UI more like the one on Reddit would be ideal. (Bluesky has recently a thread view with limited nesting, as an experimental feature.)
So that’s what I’ve built, as a web tool. You enter a URL of the root of the thread on bsky.app, and it renders the whole thread as a tree. You can use the +/– buttons to collapse and expand parts of the tree, just like on Reddit, and if you log in, you can also click the heart icons below a comment to like it:
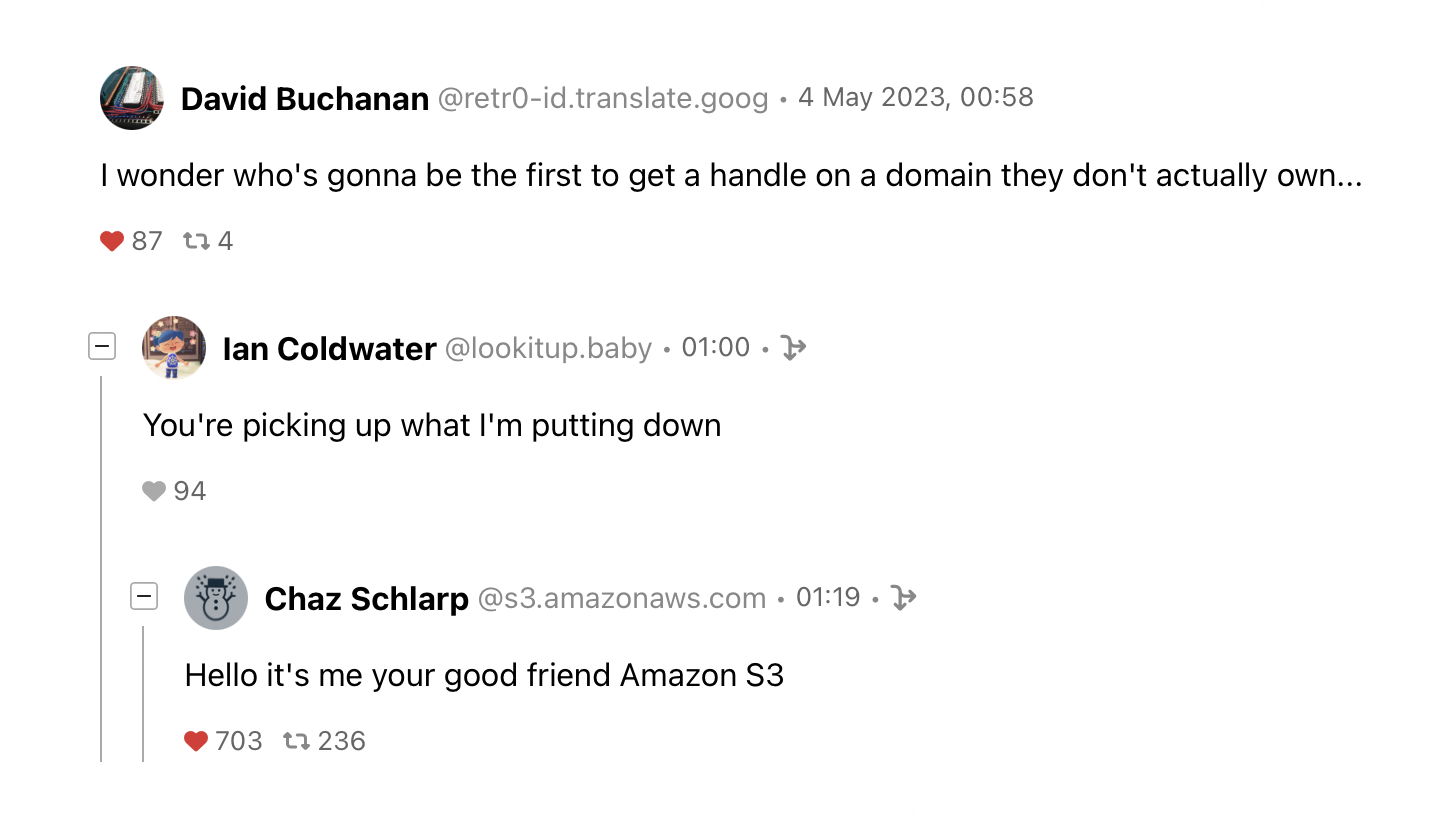
The initial version of Skythread required logging in first to see anything, but I’ve recently switched it to a different API that allows me to load whole threads without an access token. Note that the official Bluesky web app currently does not allow viewing any content unauthenticated – just like Twitter after the recent changes – so tools like Skythread, and other similar ones (e.g. Skyview) are the only way right now to share links to posts and threads with people who don’t have an account; but this is a temporary situation and Bluesky should be open to the world (for reading at least) in near future.
∕ skythread
Thread viewer for Bluesky
One app to rule them all
So where can you find me now on social media? As you might have guessed from the earlier sections, I’m spending most of the time on Bluesky now; which may be a bit strange, because that’s not where most of my friends and follows from Twitter ended up. A large part of the iOS/Mac/Swift programming community has moved to Mastodon and stayed there, with some stubbornly sticking to Twitter or posting to both. Possibly also to Threads, which I don’t even have access to.
But there’s something about Bluesky and the AT Protocol that really draws me to it… I think it’s some combination of a nicer UI/UX, tech/architecture that I like more, a new community that is only just forming, and having this feeling like I’m blazing the trail, being able to build all the tooling that doesn’t exist yet. I like being part of something that’s being created around me, flying on that plane that’s being built in the air, watching the devs build it live and feeling like I’m part of it all. I enjoy being there, I really want it to succeed, and I want to help with that as much as I can.
So I have friends on all three platforms, and even though I spend most time on Bluesky, I check all three everyday, for slightly different content – Twitter for news, Mastodon for Swift programming, Bluesky for… dopamine? And since some people only follow me here and some only there, I end up manually cross-posting a lot of things to 2 or 3 websites.
Wouldn’t it be nice to have a tool, kind of like Buffer, that can let you post to Twitter, Mastodon and/or Bluesky in parallel? There doesn’t seem to be, so I’ve decided to build one myself :] This one isn’t available yet and it still needs a lot of work before I can call it an “MVP”, but it’s going to look something like this:
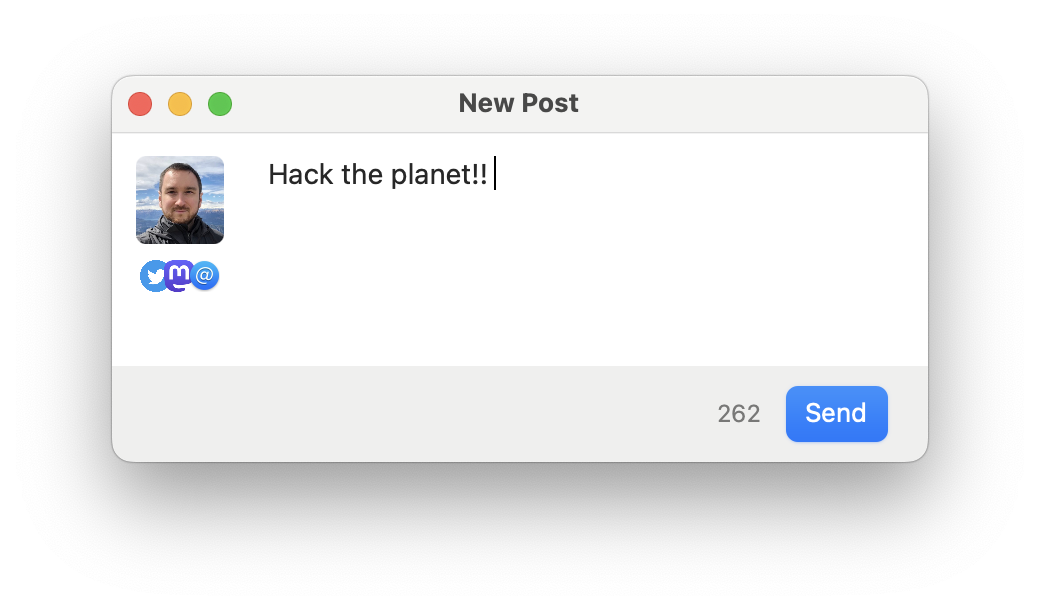
In the meantime, you can follow me here on any of these platforms – listed in the order of preference :)
- 🦋 Bluesky: @mackuba.eu
- 🦣 Mastodon: mackuba@martianbase.net
 Twitter: @kuba_suder
Twitter: @kuba_suder
2 comments:
Jack Lo Russo
Love your work here mate!
I totally went through a similar process in the aftermath of the death of Twitter. Went back to Mastodon only to find the server I’d moved to in the past (full of web dev people) doesn’t exist anymore. So now I had two dry husk Mastodon profiles — the original that still sort of exists since account portability is really strange over there, and this dead one. I couldn’t bring myself to make another one.
Then I joined Bluesky and honestly started vibing straight away — it *feels* right, it has the juice! Making feeds, reviving my Twitter bots as Bluesky bots, working on a mini client on my own website… It feels fun and exciting again.
Kuba
@Jack Thanks! I've actually managed to find quite a lot of my friends from Twitter on Mastodon - I saw them post account names on Twitter last year when the migration started, also used some tools like FediFinder, plus I went through everyone's follow lists and looked for people I recognize. So I've mostly rebuilt my contact network there. But I think Bluesky is probably better at finding people to follow when you don't have a good starting point, with all the public feeds where you can constantly interact with new people. (Although I guess you could use hashtags in the same way on Fedi, but only on the big instances.)